
Extremely long and complex books has always interested me. Like Game of Thrones/A song of ice and fire, I wonder how the author keeps tab on 100's of characters involved in arduously intricate storylines. One of those story lines is the Mahabharata, an ancient Indian epic involving a convoluted story of two families. The original iteration was written in sanskrit as far back as 9th century B.C. It was later translated to English between 1883-1886. The original size of the text is roughly ten times larger than the Greek epics odyssey and iliad combined. Such a large corupus would be a golden playground to find interesting information and that is what I set out to do. This project is a part time activity for learning and also for fun purpose. Let's dive in and take a look at the dimensions of the corpus.
I wanted to find few of the important things from the books. One has to keep in mind that I have not read the corpus previously. All information I find are new to me as well. Lets's take a look at the the key points I want to mine,
- Find who are the main protagonists of the story!
- Find their description or how they are viewed in the literature!
- What’s the general sentiment of the book?
- How can we extract similarity between entities in the corpus?
- For the last part, all kids who grew up in India have heard this story of how one of the main characters, Arjuna was exiled and how he travelled the subcontinent. I wanted to map the path they took over the years. How can we do that?
Who are the protagonists of this story?
For the first problem, it is probably the simplest one. In any book or fiction, the protagonists usually tend to be the most mentioned characters.
And this corpus is no different. Using, a library like NLTK or Spacy, we can extract the Name entities of the corpus, the filter out the proper nouns tagged as
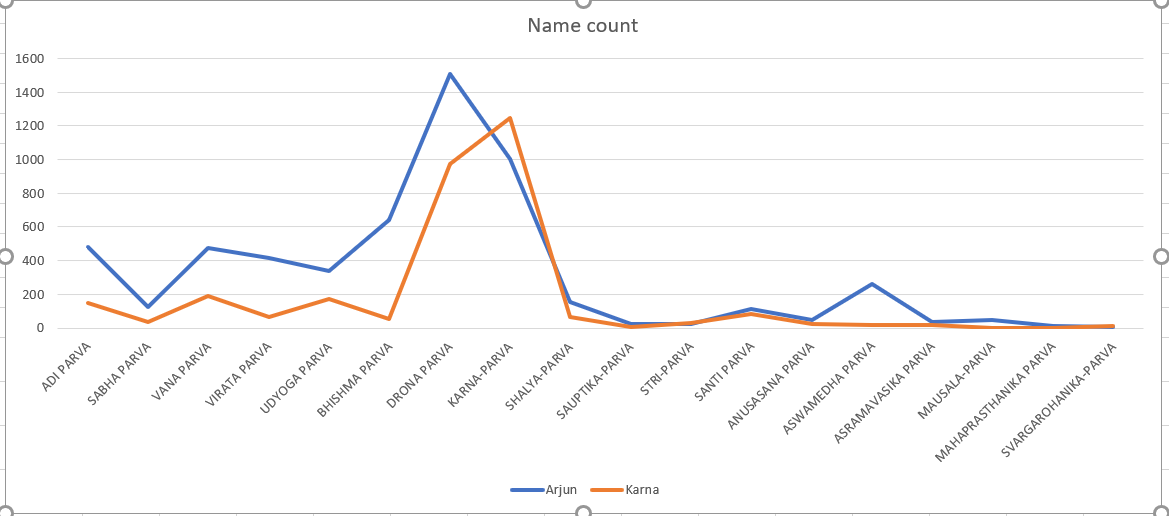
"PERSONS" and find the most mentioned ones. Two of the main protagonists of this story were Arjuna and karna. They both were mentioned more than 10,000 times in the
corpus. We can also, find the chapter level mentions of the characters and plot this data to see how relevant in the story line they were. Looking at the plot, looks
like they fall of somewhere in the middle of the book. Wonder why? If you guessed they died, you are correct.
Now how were our main characters? To do this, I counted the adjectives used to describe these two characters. Looks like they both are mighty and fierce, as all protagonists of
hero's journey stories.


Sentiment of the corpus
Another interesting part is to see the overall sentiment of the story. How it begins, how it moves forward and how it ends. To compute the sentiment scores
a library called TextBlob was used along with spacy. The positive sentiments had an accuracy of 68% whle negative intensity had 72%. Now lets plot the per chapter
sentiment and see how the mood of the book flows.
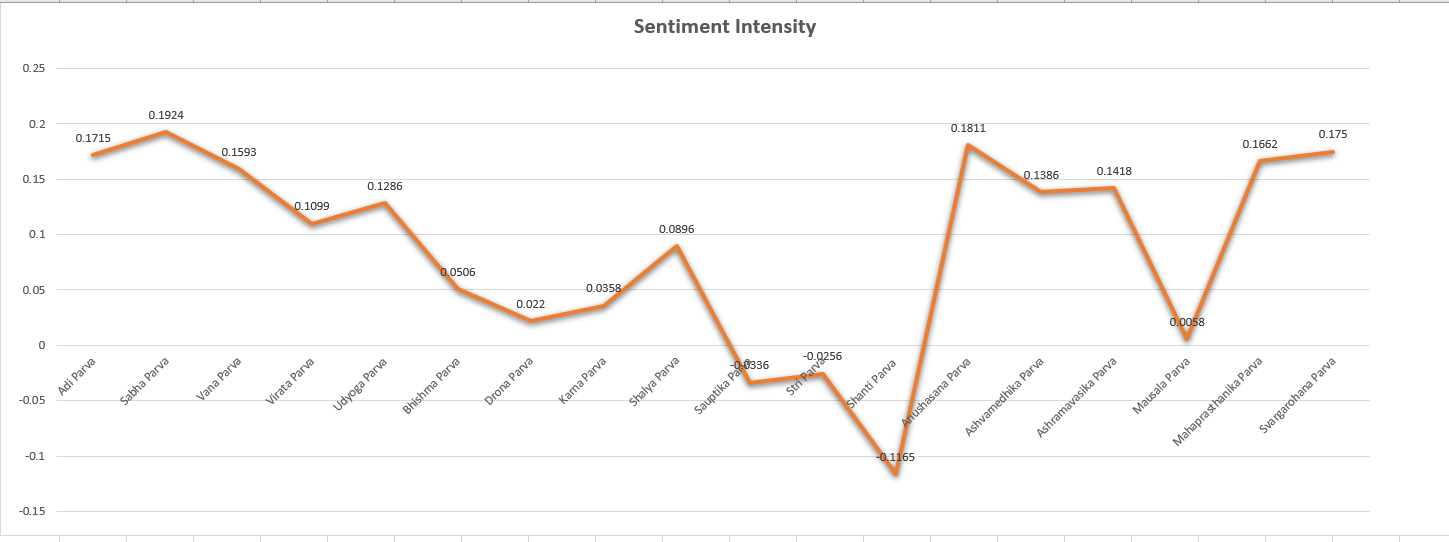
The book starts off on a high note and gradually decline over the chapter, in the middle chapters the war between the two families intensifes. And at around 11th chapter, the Two main characters die, and the sentiments takes a dive into the negative territory. Finally as the conflict resolves the curve moves back to the positive range and then it drops again around chapter 18, this is because another main character called 'Krishna' dies in the story. This is a over simplification offcourse, there might more intricate reasons on twisting of the curve in every chapter. Someone who understands the story might be able to give the correlations here.
Relation between characters
Another interesting thing to study is to find the characters of the story and whom they are close with without reading the corpus.
This can be done by visualizing the word embedding vectors by plotting them on a latent space. I first converted all the words from the corpus
into a vectors using tf-idf and then the vectors were plotted with t-distributed Stochastic Neighbor Embedding or t-SNE. t-SNE is a non linear dimensionality
reduction technique that is particularly useful to visualize high dimensional vectors in 3D space by converting similarities between data points to joint probabilities.
Along with similar techniques like PCA, it is extensively used in NLP for visualization purposes. Now let's take a look at how our corpus looks like in a 3d space.
Well, that doesn't really convey much information. To make the data points more precise and that since we are only looking for character relations,
a filter of pronouns were applied to the corpus before visualization. Now lets take a look.

Athough we cannot see in detail the features represented in this 2D picture since the scatter plot is in 3D space, we can infer anyway that the characters are seperated into factions or cluster of words which indicate their families or relations with their story counterparts. It's pretty cool that we can mathematically infer the details of the world without reading about it.
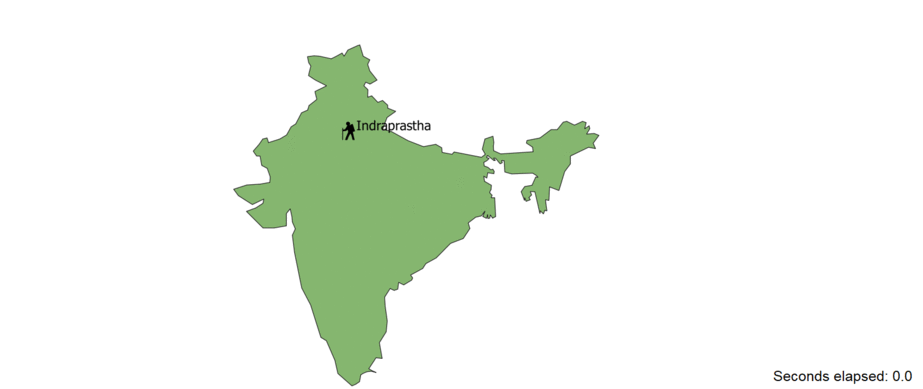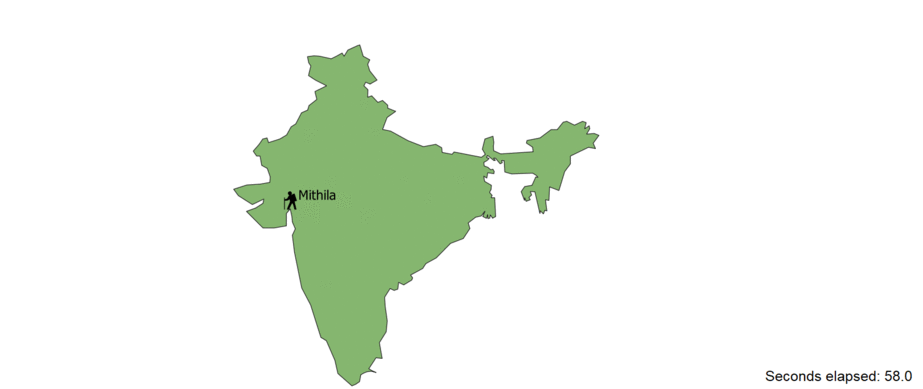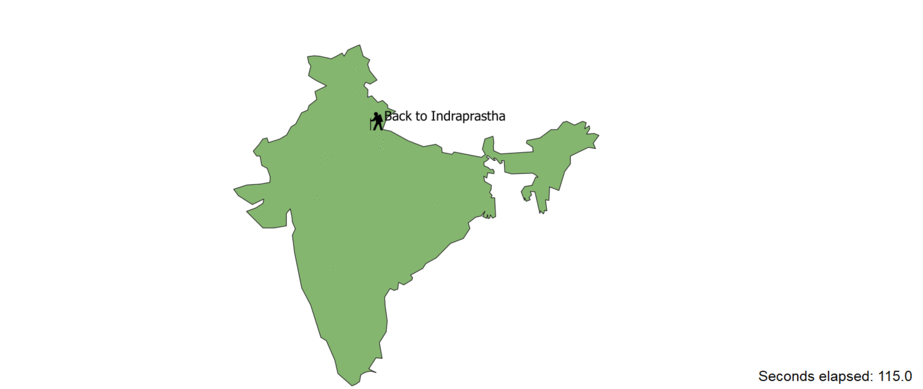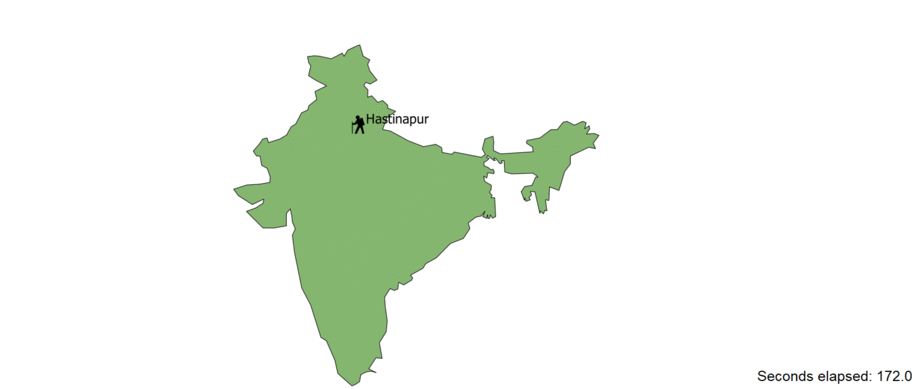
Plotting the travels of the main character
This was the most challenging part of the project. For this, the information needed are the the time and location pertained
only Arjuna. To do this, I filtered all the sentenced that mentioned the character and sorted them according to their occurence in the corpus.
The applying NER, verbs such as "travelled towards", "walked", "ran" etc along with their supporting nouns were extracted. Then only the place and
noun pairs were used as the final data points. Finding corresponding locations in the modern world took some research on the internet and they latitute-longitude were
obtained. Then this was plotted on a map of india with QGIS and kapwing software. You proably have already seen the GIF from the thumbnail.
but let' take a look at the result again.
You have reached the end of the article. This project was interesting to me. As it was my early days of learning data science and NLP in particular, I learnt a lot about word embeddings, word processing libraries like NLTK and how to visualize the mathematical part of textual data. I hope you found the mined information interesing as well. If you are further interested, you can find the code for this project in my github. Thank you and have a cookie.